Machine Learning Lifecycle (ML lifecycle) คือ กระบวนการทำ Machine Learning วนซ้ำอย่างต่อเนื่องเริ่มจาก raw data, data prep, training model และ deployment เพื่อให้มีความพร้อมในการนำไปใช้งานสำหรับ user
MLflow Registry ช่วยให้นักพัฒนา ML มีศูนย์กลางสำหรับการจัดการ ML Lifecycle และสามารถแชร์ สร้าง และเก็บโมเดลในองค์กรร่วมกันได้
เมื่อลงทะเบียนโมเดล จะสามารถใส่คำอธิบายประกอบโมเดลที่ลงทะเบียนด้วย metadata ที่เกี่ยวข้องและจัดการ ML Lifecycle ยกตัวอย่างคือการมีแบบจำลองใน Staging environment และจัดการ life cycle ก่อนนำไปยัง Production
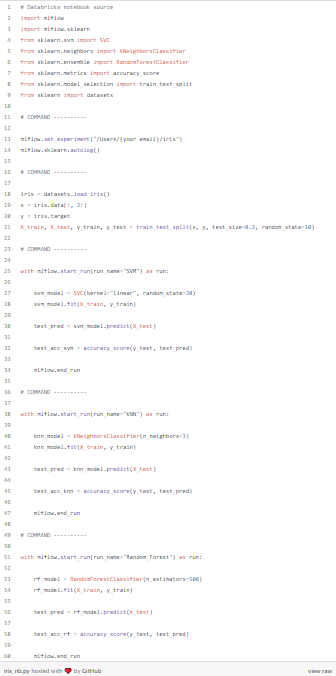
นอกจากนี้ยังสามารถทำการเลือก run แต่ละตัวแล้วทำการกด Compare เพื่อทำการเปรียบเทียบ Metric หรือ parameter ของแต่ละ run ได้อีกด้วย จะเห็นได้ว่าจากการรันเทียบ 3 โมเดลนั้น Random Forest มีประสิทธิภาพดีที่สุด
ส่อง Artifacts ที่ได้จากการรันโมเดล หลังจากการรัน model แล้ว MLflow จะมีการสร้าง Artifacts ของ model นั้น ๆ ขึ้นมาให้ โดยสามารถเข้าไปดูได้ใน Experiement แล้วเลือก run ของ model ที่ต้องการจะเห็นว่าใน Artifacts ที่ได้จะมีดังนี้
MLmodel
conda.yaml
model.pkl
requirements.txt
ส่วน metric_info.json และ training_confusion_matrix.png เป็นไฟล์ที่เก็บเพิ่มเข้ามาเพื่อบันทึกผลลัพธ์ run ของ model อันนี้ไว้
มาลอง Register Model ผ่าน MLflow จากการเปรียบเทียบจะทำการเลือกRandom Forest นำมา register model เพื่อนำมาใช้งานต่อไป โดยเลือกไปที่ run ของ model ในหน้า Experiments แล้วกด Register