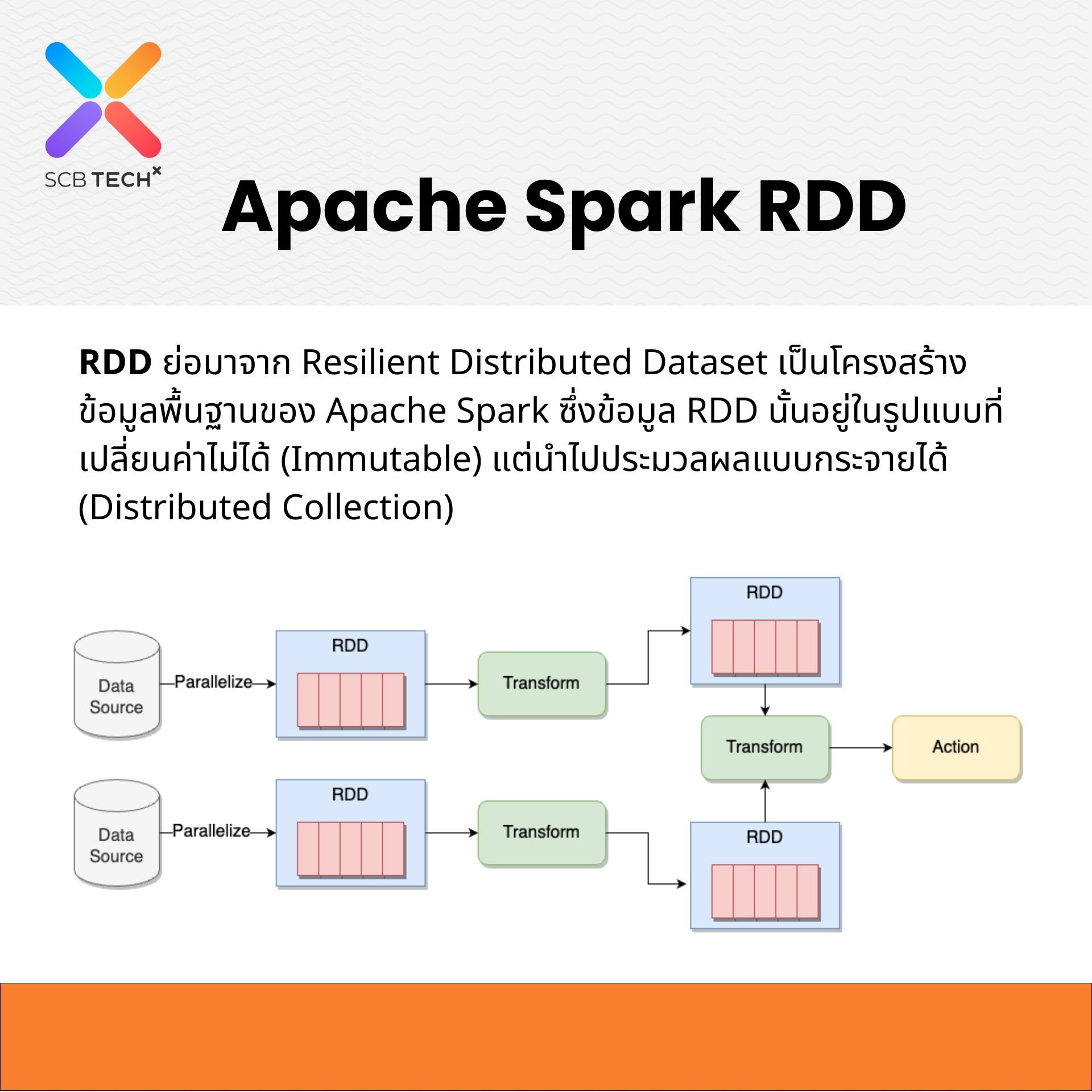
ไทย
นักพัฒนาที่เพิ่งเริ่มใช้ Apache Spark อาจลังเลว่าจะเลือกใช้วิธีการจัดการข้อมูลอะไรดีกว่ากันระหว่าง Apache Spark RDD กับ Apache Spark DataFrame วันนี้จึงขอชวนกูรูด้าน Data คุณเบนซ์ ธนภัทร ซู Data Engineer จาก SCB TechX มาช่วยแนะนำว่า Apache Spark คืออะไร พร้อมเปรียบเทียบคุณลักษณะต่างๆของวิธีการจัดการข้อมูลทั้ง 2 วิธีมาให้ทราบกันแบบ 1 นาทีจบค่ะ
Apache Spark คือ เครื่องมือที่ใช้จัดการ Big Data เริ่มพัฒนาโดย University of California, Berkeley’s AMPLab ต่อมาได้ทำการย้ายโครงการพัฒนาไปให้ Apache Software Foundation ซึ่ง Apache Spark มีวิธีการจัดการข้อมูล 2 แบบหลักๆสำหรับการทำงานกับข้อมูลแบบกระจายคือ Resilient Distributed Datasets (RDD) และ DataFrame โดยการจะเลือกใช้อะไรนั้นขึ้นอยู่กับงาน และลักษณะของข้อมูลเป็นสำคัญ
ท้ายนี้บริษัท SCB TechX ให้บริการด้านการจัดการข้อมูลแบบครบวงจร TechX Data Platform ที่คิดค้นและออกแบบโดยผู้เชี่ยวชาญที่มีประสบการณ์ตรงในการพัฒนา และ Deliver Data ให้แก่องค์กรชั้นนำมากมาย
หากท่านใดสนใจสามารถสอบถามข้อมูลเพิ่มเติมได้ที่ contact@scbtechx.io
อ่านรายละเอียดเพิ่มเติมที่ https://bit.ly/3Q2a9vd
ในยุคที่ “ออนไลน์” ก…
ปัจจุบันนี้ ระบบดิจิ…
“PointX” (พอยท์เอกซ์…
If you want to message us, please give your consent to SCB TechX to collect, use, and/or disclose your personal data.
We have receive your message and We will get back to you shortly.