


บทความนี้ เราจะโฟกัสที่ขั้นตอนหลังจากที่เราได้ติดตั้งและเซ็ตอัป ELK Stack ให้รันได้เรียบร้อยแล้ว โดยประเด็นสำคัญคือการบริหารจัดการและปรับขนาด (Sizing) ของระบบ เพื่อรองรับปริมาณ Log ที่เพิ่มมากขึ้นอย่างต่อเนื่อง พร้อมทั้งรักษาประสิทธิภาพของทั้งกระบวนการเขียน (Write) และอ่านข้อมูล (Read) ให้ทำงานได้อย่างราบรื่น โดยการติดตั้ง ELK Stack ซึ่งในครั้งนี้ผมจะอ้างอิงตามมาตรฐานการใช้งานทั่วไปตามภาพครับ

อย่างแรก เราต้องประเมินปริมาณของ Log (Log volume) ที่จะเกิดขึ้นในแต่ละวันได้คร่าว ๆ ก่อน ว่าจะมีประมาณเท่าไหร่ เพื่อใช้เป็นข้อมูลในการทำ Sizing ของระบบได้ถูกต้อง จากนั้น มาพิจารณาประเด็นหลัก ๆ ที่เราต้องคำนึงถึง ได้แก่
1.Sharding
การทำ Sharding ใน Index Pattern ของเเต่ละ Index Type เพื่อกระจายการทำงานไปหาในเเต่ละ Node แบ่งการทำงานให้เท่าๆกัน ไม่ไปหนักที่ Node ใด Node หนึ่ง และ Scale จำนวนเครื่อง Data Node แบบ Scale Out โดยการ Set จำนวน Shard ในเเต่ละ Index Template นั้น เราต้องประเมินว่า Log Size ในเเต่ละวันมีประมานเท่าไหร่ เพราะ Shard เล็ก หรือ ใหญ่เกินไปจะไม่ดีต่อ Performance ของ Elasticsearch Node โดย Shard หนึ่งควรมีขนาด ไม่เกิน 50 GB ดังนั้นถ้า Index มีน้อยกว่า 30 GB ก็ไม่จำเป็นต้องแยก Shard ถ้า Index มี Size 90-200GB GB ก็ควรจะ Set 3-5 Shard ถ้ามากกว่านั้นอีกก็ 5-10 Shard จากนั้นเราก็มาดูต่อว่า พอได้จำนวน Shard ทั้งหมดที่จะเก็บไว้ใน Hot Tier Data Node เเล้ว ก็จะไปทำ Sizing Hardware ครับ
2.Hareware Sizing
ตาม Document ของ Elastic แนะนำให้ 1 GB ของ Heap JVM Memory ของเครื่อง Hot Data Node รับจำนวน Shard ได้ 20 Shards ดังนั้น ถ้าเรามี Shard ที่ต้องเก็บต่อวัน จำนวน 240 Shards ตัว set replica ก็จะกลายเป็น 480 Shards ถ้าเรามีเครื่อง Data Node 3 เครื่อง เเต่ละเครื่องก็ต้องรองรับ 160 Shard ดังนั้นควรจะมี JVM Memory อยู่ประมาน 8 GB ซึ่งตามหลักเราควร Set JVM ไว้ ครึ่งนึงของ Memory Hardware เพื่อเหลือให้ OS ดังนั้น Ram ของ Node ก๊คือ 16 GB ส่วน CPU อันนี้จะแล้วเเต่ Usecase ของการใช้งาน Elasticsearch ถ้า Search ไม่เยอะเเต่เก็บเยอะ หรือใช้งานแบบ Search Vector โดยเเนะนำให้ไปดู Sizing Cpu/Ram ของ Elastic Cloud ใน Cloud.Elastic.Co ในเเต่ละ Usecase เพื่อเป็นแนวทางครับ เพราะเค้าจะคำนวนอัตราส่วน Cpu/Ram กับ Througput ที่เข้ามาดีเเล้ว
อาจมีคำถามว่าเราต้อง Set ตามหลักการด้านบนทั้งหมดเป๊ะเลยไหม?
ก็ต้องบอกว่าไม่ต้องเป๊ะตามตัวเลขขนาดนั้น เเต่ก็ไม่ควรห่างจากด้านบนมากเกินไป เช่นถ้าเป็น Environment Nonprod Size ของ Index ในเเต่ละวันก็จะไม่ใหญ่เท่าไหร่ เราก็ไม่จำเป็นต้อง 1 GB Heap / 20 Shard เพราะจะเปลืองค่า Hardware เยอะเกินครับ เเต่ก็ไม่ควรห่างจากอัตราส่วนด้านบนมากเกินไป ส่วนที่ Production มักมีปริมาณ Log มากอยู่เเล้วต่อ Shard ก็ควรทำตามอัตราส่วนนี้ครับ
คำถามต่อมาคือจะเกิดอะไรขึ้นถ้า จำนวน Shard เราเยอะเกินไปเมื่อเทียบกับ Heap?
สิ่งที่จะเกิดขึ้นคือจะมีการทำ Garbage Collection ถี่มากขึ้นเรื่อยๆตามจำนวน Shard → Heap Memory สูงจนชน Limit เเล้ว → Cpu จะวิ่งสูงเกือบ 100% ตามลำดับ ซึ่งต้นเหตุมาจากการทำ Garbage Collection ถี่โดยเราสามารถดูได้จาก Monitor Console เมื่อเราได้ Enable Monitoring ใน Elastic Cluster ไว้ครับ
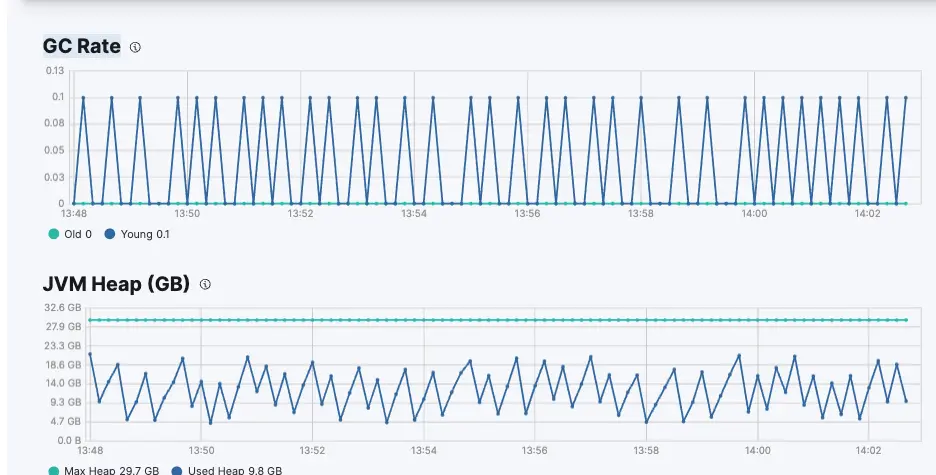
จาก Graph GC Rate ซึ่งเป็นจำนวนการทำ Garbage Collection ในช่วง 10 วินาที ถ้าตอนที่ มีปัญหา Shard กับ Memory ไม่ Balance แล้วเรามาดูกราฟ เห็นมันวิ่งแถวๆ 0.3 – 0.5 ตอนแรกเราอาจจะคิดว่า 0.3 – 0.5 ดูน้อย เเต่จากประสบการณ์ ถ้าเริ่มขึ้นไปที่ 0.3 – 0.5 ก็จะเริ่มทำให้ Cluster Restart บ่อยๆ และ User รัน Query ช้ากว่าปกติมาก ดังนั้นไม่ควรใช้ กราฟนี้เกิน 0.1 ครับ ซึ่งปกติเเล้วเราก็จะใช้ ILM (Index Lifecycle Management) หรือ SLM (Snapshot Lifecycle Management) เพื่อตั้ง Policy หรือจะรวมกับการใช้ Data Stream เพื่อ Roll Over Index ไป Data Tier ต่อไป ในการควบคุมจำนวน Shard ใน Data Node นั่นเองครับ เมื่อเราทำการ Config ทั้ง Index Template และ Sizing Hardware Size ของ Elasticsearch Cluster ให้เหมาะสมเเล้ว ต่อไปจะเป็นเรื่อง การ Tuning Filebeat + Kafka + Logstash ให้รองรับปริมาณ Log ที่เพิ่มสูงขึ้นครับ
ในส่วนของ Filebeat จะเป็น Agent เล็กที่อยู่ในทุกๆ Node ที่จะกวาด Log เเล้วส่งต่อ ไม่มีการ Process Data มาก เราจึงปรับ Cpu ขึ้นบ้าง เเต่ Config Default ที่ติดมามักทำงานได้ดีอยู่เเล้ว จึงไม่มีปัญหาเรื่อง Performance เมื่อ Log มากขึ้น หลังจากนั้น ส่ง log ไปที่ Kafka เพื่อใช้เป็น Buffer ในกรณีที่เกิด Back Pressure จาก Elasticsearch หรือ Logstash ขึ้นมา Log จะได้ไม่หายครับ โดยเราควรจะวัด Througput ของ Log อยู่สม่ำเสมอ โดยหลักการทั่วไปคือปรับ Topic Partition ใน Kafka 1 Partition ต่อ 1 MB/Sec Througput ครับ เพื่อเพิ่มการทำงานแบบ Parrarel ในบางกรณีที่ Partition ต่ำเกินไปเทียบกับ Througput จะทำให้เกิด Log หายได้ครับ
ต่อไปจะเป็น Logstash ดูด Log ใน Kafka ส่งให้ Elasticsearch ซึ่งปัญหาที่มักเจอคือ Log มาช้า ต้องไปดูว่า Elasticsearch มี Cpu รันสูงมั้ย ถ้าใช่ก็จะเป็นที่ตัว Elasticsearch ทำการ Index Data ไม่ทันก็ต้องไปปรับ Size Cluster ขึ้น เเต่ถ้า Elastic Search Cpu ไม่สูง เเล้วมาดู Logstash ก็ Cpu/Memory ไม่สูง เเต่ Log ยังเข้าช้าอีก ก็แปลว่าตัว Logstash ทำงานใช้ Resource ได้ไม่เต็มที่โดยตัว Logstash นั้น การ Scale Up (เพิ่ม Spec) มักได้ผลดีคุ้มกว่า Scale Out (เพิ่มจำนวน Logstash) โดยเราต้องไปเพิ่ม Config ใน Logstash Pipeline Pipeline.Batch.Size เพื่อเพิ่มจำนวน Log ในการส่งแบบ Batch ไป Elasticsearch โดยต้องเพิ่ม JVM และ Memory ตามขึ้นไปด้วย เเล้วต้องเพิ่มเท่าไหร่ อันนี้ขึ้นกับ ว่า Message Log ใหญ่เเค่ไหน โดยเราควรจะทำการ Performance Test ดูครับ เพราะถ้าปรับ Pipeline.Batch.Size เพิ่มอย่างเดียวเเต่ไม่ปรับ JVM และ Memory ขึ้นตามไปด้วยก็จะทำให้เกิดการ OOM Kill ได้ครับ เเล้ว Pipeline.Workers ซึ่งเป็นเหมือนฝั่ง Cpu ที่เพิ่ม Thread ของ Logstash ควรเพิ่ม Pipeline.Workers ให้เท่ากับ Cpu Core ของ Logstash ครับ
ถ้า Application มี Log เข้ามาในปริมาณมาก ก็ควรจะมีการทำ Performance Test เพื่อเตรียมแผนในการ Scale ระบบครับ เช่นตารางด้านล่างไว้เทียบว่าตอนนี้ Log มี Throughput เข้ามาประมาณเท่าไหร่เเล้ว ในอนาคตถ้ามี TPS เยอะขึ้นจะ Scale ระบบไปที่ตรงไหน ซึ่งอย่างที่บอกด้านบนว่าตัว Logstash Batch Size กับ JVM ของ Logstash นั้นก็จะขึ้นอยู่กับขนาดของ Log message ซึ่งจะแตกต่างกันครับ
ท้ายนี้หากองค์กรของท่านกำลังมองหาโซลูชันด้าน DevOps ช่วยปรับรูปแบบการทำงานให้เป็นอัตโนมัติ ลดต้นทุนการทำธุรกิจ SCB TechX พร้อมเป็นโซลูชันที่ช่วยพัฒนา และ Deliver ผลิตภัณฑ์และบริการออกสู่ตลาด ต่อยอดองค์กรของท่านให้เติบโตอย่างยั่งยืน
สนใจบริการโปรดติดต่อเราที่ https://bit.ly/4etA8Ym
อ่านรายละเอียดเพิ่มเติมคลิก https://bit.ly/4dpGl6U



