
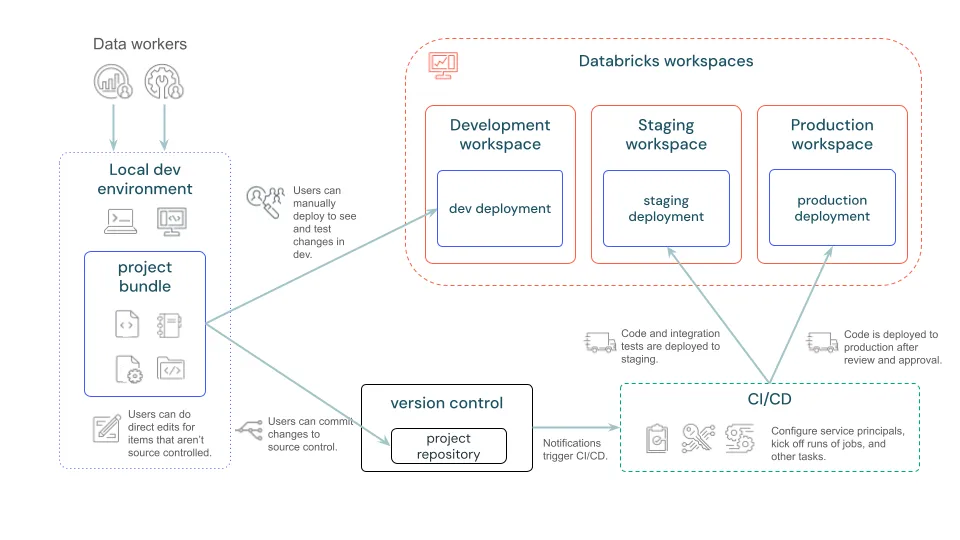
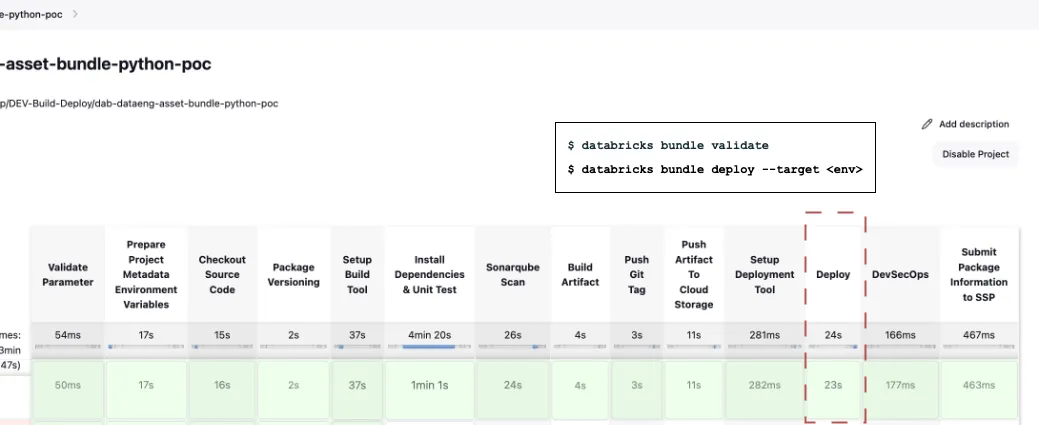



: As 2024 comes to an end, let's explore the key technologies and trends that have shaped the DevOps and…

Independent Artist Management, commonly known as iAM, is a prominent artist management company and music label in Thailand. The company…

Card X Co., Ltd. (CardX) is a financial services company under the SCBX Group, specializing in credit cards and personal…
